The following are my notes on a set of videos by Andrej Karpathy (video 1, video 2) that provide an excellent high level overview on what LLMs are and how they’re trained. It is by no means meant to supplement the content of the videos and recommend giving them a watch yourself.
Overview
An LLM can be distilled into two files:
- The model parameters
- Code to run the forward inference of the NN (~500 lines of c code)
Together you could take these and run the model locally if desired. Model training tends to be the more involved and computationally intensive aspect opposed to inference which is quite well understood as a forward pass through the network.
What is the NN doing?
Given a sequence of words the neural network produces a prediction of which word comes next.
- Turns out that next word prediction forces the neural network to learn a lot about the world.
- If you’re the NN and your objective is to predict the next word then when looking at some context you have to learn a ton about the world which is ultimiately compressed in the network’s parameters.
- The Neural Network in a sense “dreams” internet documents. If you ask it to produce some text it doesn’t parrot the text it has seen but it mimics the form popualted by content it thinks is correct. This is where hallucinations come from.
How does the Neural Network Work
- We train a transformer nerual network architecture
- we know all the mathematical operations that are happening at each step in the network. But the billion parameters are dispersed through the network.
- we know how to iteratively adjust them to make it better at prediction (backprop)
- we can measure this works but we don’t really know how the billion of parameters collaborate to do it.
- some work is done here in a space called interpretability
- We know that to some level the LLMs build and maintain some kind of knowledge database but it is a bit strange and imperfect
Pretraining
The general idea is to take a large chunk of the internet (~10TB of text), take a group of GPUs (~6000) and run for ~12 days to obtain parameters that can be thought of as a zip file of the chunk of the internet. While a zip file is lossless, this parameter training is a lossy compression.
- At this point once pretraining is done, the model can produce a a corpus of text in some mimicked form. Essentially just produces these “documents” or webpages.
- in a sense it is an internet document sampler and doesn’t actually give answers to inputs, it just produces documents/text based on a distribution
- The knowledge from the training data is distilled in the model
Step 1: Download and preprocess the internet
- FineWeb by hugging face provides an overview on how they approached data collection to obtain and create a large corpus of training data from the web
- where do you get the raw data?
- you can crawl it yourself like OpenAI and Anthropic do
- You can use a public repository such as one provided by CommonCrawl. (What is done by FineWeb)
- The process consists of multiple steps and is quite extensive. Giving the document a read is recommended.
- where do you get the raw data?
- What we get is a massive amount of internet text which we can concatenate into a massive blob.
Step 2: Tokenization
- The way our Neural Networks work is that they expect a one dimensional sequence of symbols and they want a finite set of symbols that are possible
- We have to decide what are our symbols and then we have to represent our data as this one dimensional sequence of those symbols
- Currently we have a one dimensional sequence of text -> binary -> sequence of bytes (256 possible symbols 0-255)
- More state of the art systems go a step further to find consecutive bytes that are common and combine these groups of bytes into a new symbol. Each time we do this we are decreasing the sequence size but increasing the number of symbols.
- In practice ~100,000 symbols is a good vocabulary size
- More state of the art systems go a step further to find consecutive bytes that are common and combine these groups of bytes into a new symbol. Each time we do this we are decreasing the sequence size but increasing the number of symbols.
- This concept of converting text to tokens is the process of tokenization
- tiktokenizer is a useful site to explore tokenization for various models. You’ll see by pasting a lot of text that oftentimes tokenizing doesn’t align with words but partial words or groups of words.
Step 3: Neural Network Training
- We want to model the statistical relationships of how these tokens follow each other in the sequence
- We take a window of tokens randomly. The window can range from (0-max_size). We call this window the context and we feed it the sequence through the neural network.
- The input to the network are sequences of tokens of variable length
- The output is a prediction of what comes next
- Because our output vocabulary is 100,000 symbols/tokens, the neural network is going to output a tensor of that many numbers and all of those numbers correspond to the probability of that token coming next in the sequence.
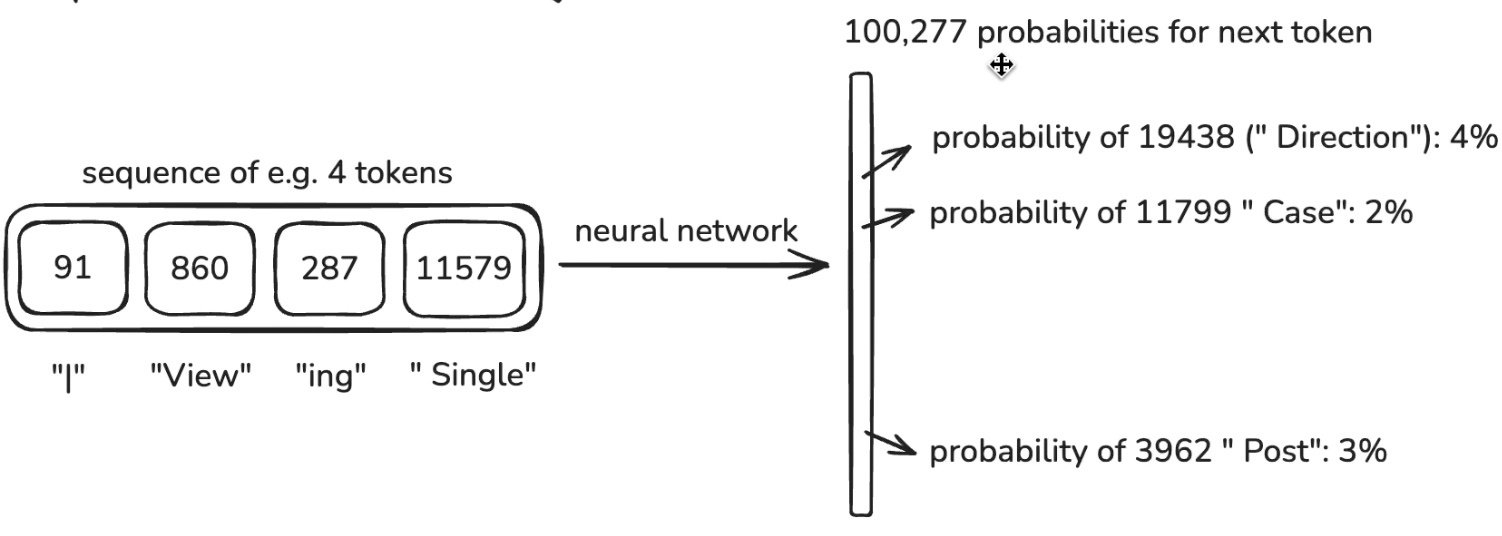
- Initially the NN is randomly initialized
- We sampled this window from our dataset and we know what comes next and that’s the label/correct answer.
- In the image above if the correct token is
3962then we want the probability of that token to be higher and the other tokens to be lower - We have a way of mathematically updating the network to nudge towards this with backpropagation
- In the image above if the correct token is
Base Models
What we get at the end of training is a base model that is quite good at producing coherent text blobs. The base models are often not released by companies but some companies such as Meta with Llama and OpenAI with GPT 2. If you look at the GPT-2 repository on github you’ll see the python code that describes the sequence of operations that they make in their model. This bit of code implements the forward pass of this network. The second thing that is needed to release the model is the final parameters. In the case of GPT-2 its a list of ~1.5 billion numbers that are tuned to perform text prediction.
- GPT-2: 1.6B params trained on 100B tokens
- Llama 3: 405B params trained on 15 trillion tokens
Note This is a helpful 3D LLM Visualizationtool of a real Neural Network Transformer Architecture in production. Its helpeful to view the flow of data from input tokens to the output along all the weights
The base model is a compressed knowledge of the internet. Somewhat like a zip file but it is lossy. You can elicit knowledge from the model by prompting it and leading it with something to almost “autocomplete”. What is important to know is you can’t generally trust the output since the knowledge is vaguely contained in the weights. It’s just a sampling over probabilities of text. That being said, you do get out some of the knowledge that is somewhat correct. At the same time you don’t want regurgitation which is the exact output of its training input.
Another important piece to know is that the training input has a knowledge cutoff date in the base model. Its trained on data that’s collected up to some date. Which means events, information, findings that occured after that date are not known in the base model. The model will still give predictions but will hallucinate the answers.
- The base model is a token-level internet document simulator
- It is stochastic/probabilistic - you get new output every time you run
- It “dreams” internet documents
- It can also recite some training documents verbatim from memory (regurgitation)
- You can use it for applications such as translation with clever prompts (i.e English:Korean;English:Korean; … and then the base model will pick up this pattern and continue with new words if we left it at “English:”)
Post-Training (Supervised Finetuning)
- The assistant aspect comes from fine tuning the model. We would like to give questions and have the assistant give us answers
- The process behind finetuning is to keep the optimization identical to the pretraining step, but we swap out the dataset we are training with to a set of human prompts and ideal assistant answers.
- Instead of training on internet corpus/documents we swap it out with data we collect manually. Where humans will fill out the ideal response to answer the prompt in the format below.
- We care more about quality over quantity here
Test Set:
<user>
prompt
<assistant>
answer
To encode the conversation into the input tokens for training the input has to be converted to a special format. Each company does it does it differently but for gpt-4o they use the following:
user: what is 2+2?
assistant: 2+2=4
# gets converted to
<|im_start|>user<|im_sep|>What is 2+2?<|im_end|>
<|im_start|>assistant<|im_sep|>2+2=4<|im_end|>
<|im_start|> [role] <|im_sep|> [response] <|im_end|>
- im stands for imaginary monologue
- im_start, im_end, im_end are special tokens that have not been trained on, they are added in this fine tuning step.
Now we have a one dimensional sequence of tokens that we can use to train the same way we did in the pretraining step.
- After finetuning we have an assistant
- The model now understands that it should produce an answer format that is helpful to what the prompt is while still using all the knowledge they developed during the pretraining phase
Inference
What this looks like for inference now is that we pack the user’s prompt surrounded by these new tokens <|im_start|> user <|im_sep|> prompt <|im_end|> <|im_start|> assistant <|im_sep|> and from here the next token prediction picks up from the assistant’s role and picks the next word in the sequence generally to fulfill the user’s prompt.
One of the challenges we face now is how to avoid hallucinations. We have to interrogate the model to find out what it doesn’t know. Once we find something it starts to hallucinate and for sure does not have knowledge we add that to our training set with the correct answer being “I don’t know” therefore the model will start to trigger “I don’t know” as a response rather than hallucinate for something beyond its knowledge.
In reality we can do better than saying “I don’t know” but rather we can have the model use tools to improve its knowledge and find information. We can have the model emit a token saying <search_start> [query] <search_end> which when we see being emitted we pause running inference and instead we can go perform a query on bing or google. We grab the results, paste it into the context window/add it to the corpus we’re generating and then continue running inference. The context window can be thought of like the working memory of the model. Just like humans we have knowledge but might need to refresh ourselves and bring things into our memory again. Adding <search_start/ends> tokens again requires us to add examples that do this into our training set.
- knowledge in the parameters == vague recollection (e.g. of something you read 1 month ago) knowledge in the tokens of the context window == working memory
- For thinking tasks or tasks where we need computation it is often bad to have the model just one-shot an answer. This is because in its token prediction it has to somehow perform all the “computation” correctly to arrive at the answer. If instead you asked it to work through a problem it will build up the context and the numbers and variables and be able to reason and that’s because more context/tokens is necessary to have the model “think”. If possible for computation/counting tasks try to use a tool if possible (code, calculator, etc.)
- Ask chatGPT “how many dots are in this message? …………………………………………………………………………….” and it will respond with an arbitrary number. If instead you have it use code it can perform the computation correctly and report the result.
Post-Training (Reinforcement Learning)
We don’t really know what process is best for the LLM to produce the right answer. As such we give practice problems and see how they behave. Under a process of trail and error, it needs to find for itself what token sequence and pattern helps it get to the right answer. This process is done through reinforcement learning.
we are given a problem statement (prompt) and the final answer. We want to practice solutions that take us from the problem statement to the answer and “internalize” them into the model.
Given the same prompt into the model we run it through the model to get many solutions. Some of them may succeed and some of them may not. To encourage the model towards the solutions that produced the correct answer, we take the top solutions, train on it and repeat many many times. This time instead of a human producing the best assistant’s response, they’re generated from the model itself.
RL is a little earlier and there are more nuances into how much we train on data produced from the model and how we actually pick the answers which are the best.
DeepSeek demonstrated chain of thought which is an emerging property of LLMs where in its process of creating long answers it almost backtracks, reevaluates answers, and tries different things, until it almost “reasons”. The model discovers ways to think and this comes from Reinforcement Learning, it is not something hard coded anywhere.
- This has led to the emergence of reasoning models
inspired by alpha-go which had 2 stages
- learn by imitating expert human players
- learn by self-improvement (reward = win the game) in a sandboxed environment with a very clearly defined goal in which it kept playing against itself
Can we bring this second stage to LLMs. If we only train on humans then our knowledge is bounded only by humans.
- the challenge in doing this is the lack of a reward criterion in this environment. How does an LLM know what it sampled is good or not
Reinforcement Learning from Human Feedback (RLHF)
- In this stage we use a second kind of label: comparisons
- It is often much easier to compare answers rather than writing new answers
- We take n versions of a response to a prompt and we take the higher voted response
- This is called RLHF (Reinforcement Learning from Human Feedback)
System 1 vs System 2
Humans have 2 systems of thinking
- Instinctual (2 + 2)
- Deep thought (17 * 24)
One of those problems requires us to slow down a little and processes the answer by thinking and reasoning through it.
Currently LLMs only have System 1 but we have been introducing and work is being done for what it may mean if an LLM had System 2 behaviour
Summary
Stage 1: Pretraining (~annually)
- Download ~10TB of text
- Get a cluster of GPUs
- Compress text into a neural network with training
- Obtain base model
Stage 2: Finetuning (~every week)
- Write labelling instructions (how should your assistant behave, personality, attributes, etc.)
- hire people (or use scale.ai) collect 100k quality ideal Q&A responses and/or comparisons
- Finetune base model on this data (takes ~1 day)
- Obtain assistant model
- run a lot of evaluations
- deploy
- monitor, collect misbehavior, go to step 1.
The way we fix misbehaviour is we take the incorrect answer and have the user fill in the correct response and we then fine-tune on this
Lamma by meta releases both the base model and the assistant model. So we can take the base model with all its knowledge and then fine tune it to our specialized use cases whatever that may be.
LLM Scaling Laws
- Performance of LLMs is a smooth, well-behaved prediction function of
- N: Number of parameters in the network
- D: the amount of text we train on
- we expect more intelligence “for free” by scaling